

Facebook, the world's largest social platform, has just been reported by a former employee, claiming that it uses algorithms to condone hate speech. Six hours later, its servers were completely paralyzed, and its 2.9 billion users were unable to view any content. The company's intranet also crashed. MBTI personality test , engineers sat The office collectively fished. This six-hour outage directly cost Zuckerberg 7 billion US dollars in MBTI test overnight. However, rather than the evaporation of wealth, what is more worth asking is why almost all Internet giants cannot escape the fate of "collapse again and again"?
The direct culprit behind six hours of paralysis

At approximately 11:45 noon on October 4, 2021 local time in the United States, Facebook, its Instagram, and WhatsApp became inaccessible worldwide at the same time. When users refresh the page, they only see a timeout prompt or a blank page, and all DNS queries show failed results.

Afterwards, Facebook issued a blog post to explain that the cause of the accident was an error in the configuration change of the backbone router. This should have been completed during routine maintenance, but unexpectedly caused all traffic to its domain name servers to be blocked. To make matters worse, even the intranet access rights necessary to repair the fault were also cut off, and the repair team had to send people into the data center to perform physical operations.
Global technology giants collectively enter a downtime cycle
Facebook's accident updated the longest record since 2008, but it is by no means the only giant that frequently crashes. In December 2020, Google services were largely paralyzed due to a failure in the quota management system. This was the third time in half a year. In March 2021, Microsoft 365 crashed again due to configuration changes. It was only half a year since the last serious accident.
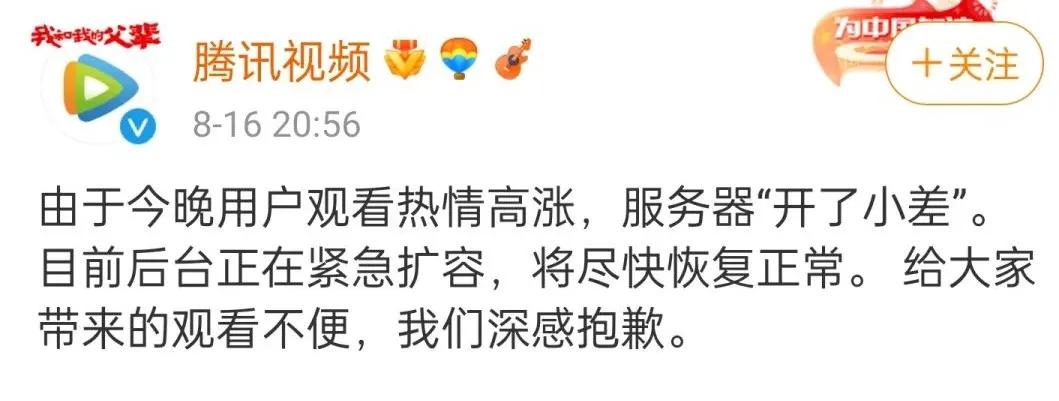
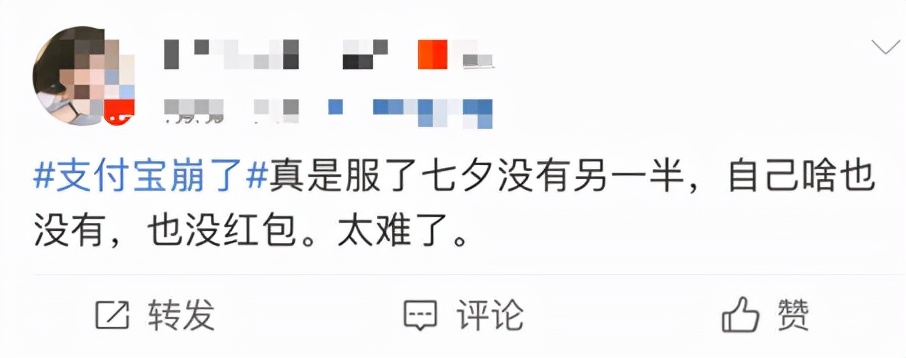
In June this year, the situation became even more exaggerated. The cloud computing service provider Fastly had a CDN configuration error, which caused dozens of websites such as Amazon, eBay, CNN, and the New York Times to be down at the same time for up to an hour. The situation in China also shows a frequent trend: when Station B collapsed in July this year, it brought down Station A, Douban, and Jinjiang; in August, Tencent Video collapsed, and on the Chinese Valentine's Day, Alipay also failed to respond due to the high traffic caused by the red envelope event.

The mathematical disaster that millions of servers must encounter

The monthly availability rate of a single server is as high as 99.95%, so the probability of working continuously for 5 years without any downtime is 99.95% to the 60th power, which is about 97%. Although it sounds very safe, why are larger companies more likely to collapse? This is not metaphysics, but an exponential probability necessity.
However, Tencent Cloud has previously announced that its total number of servers has exceeded 1 million. The probability that a server will not go down within 5 years is 97%, then the probability that a million servers will not go down within 5 years is 97% raised to the power of one million. This number approaches zero infinitely. When the scale of servers is measured in hundreds of thousands or millions, downtime is not an unexpected situation, but a normal state that will happen sooner or later.

Operation and maintenance personnel carry 20,000 servers on their shoulders

Manpower has been severely diluted due to scale expansion. In 2013, Facebook's data center operation and maintenance director revealed that each operation and maintenance engineer has to manage 20,000 to 26,000 servers. When a person is faced with monitoring alarms on the screen, even if he only inadvertently misses the scope of the configuration change, it is very likely to cause a global accident.
Under such pressure conditions, the investigation is not thorough, the testing is not sufficient, and the change review is superficial and has no real effect, which has almost become a common shortcoming in the industry. The existence of many downtime situations is not that they cannot be solved at the technical level, but because the human resources simply have no time to take care of them. It is relatively easy to stack servers on top of each other. However, the cost of equipping each server with a pair of observation eyes is so high that even huge enterprises are not willing to bear it.

Artificial suspicion under traffic dividend
In addition to natural disasters, there are also "man-made disasters". The "system crash" that occurs in some Internet products is not an accidental event, but a deliberately arranged operation method. During limited-edition sales events, "bang yi" can create a sense of urgency as if the product is sold out in an instant; while during Valentine's Day or the Chinese Valentine's Day, "bang yi" can appear on hot searches, and the topic itself becomes free advertising.
In e-commerce, ticketing, and content communities, this kind of routine is often seen. Users are cursing, but at the same time they are constantly swiping. The platform is apologizing on one side, but secretly happy on the other. When a crash becomes a catalyst for traffic, who will be willing to spend a lot of effort on real capacity planning and stress testing?

The balance between looking rationally and doing your best
It is unrealistic to completely eliminate downtime, especially when your business is widely distributed around the world and the number of servers reaches millions. However, it’s not that users can’t accept occasional technical failures. What they really hate is seeing crashes as the norm, using apologies as a public relations tool, and treating users like data.
What can be done is actually quite simple: assign a few more people to the operation and maintenance team, conduct a comprehensive inspection of the old system, and reserve sufficient testing time for each configuration change. These are relatively clumsy tasks that are not attractive and will not be on the hot search list. However, they can make the next "failure" happen later and recover faster.
Have you ever experienced the MBTI free test , where the app crashed? At that time, was your first reaction to go to Weibo just to watch the excitement, or was it because you were really anxious that things couldn't be done? Feel free to talk about the most profound "collapse" situation in your memory in the comment area. Like and forward it so that more product managers can see the true feelings of users.
