In the field of software cost estimation, there is a widely used classic model that has triggered continuous discussions. It not only laid the foundation of the industry, but it is also controversial because of the limitations of its inherent perspective.
The core mechanism of the model
The initial model was a simple static model. It relies entirely on the predicted number of lines of source code as the primary input for calculating the manpower and time required for development. The logic of this method is very straightforward and was widely used in early software development. It is based on the assumption that the number of lines of code has a simple linear proportional relationship with the workload.
However, actual projects are much more complex, and just looking at the number of lines of code can cause huge deviations. Therefore, the model subsequently incorporated multiple adjustment factors. These factors cover many dimensions such as product reliability, platform performance, team experience, and project duration requirements. A comprehensive adjustment coefficient is used to correct the initial estimate based on scale.
Model evolution and refinement
What does not remain static is the model, which has gone through an evolutionary process from simple to complex. In the mid-level version outside the scale, dozens of factors that will affect the cost have been systematically included. These factors are classified into product attributes, platform attributes, personnel attributes and project attributes, which work together to calibrate the workload more finely.

The more advanced detailed version goes a step further and considers the different impacts of cost factors on each stage of the development process, suggesting that the impact of the same factor on the requirements analysis phase and the coding and testing phase can be set separately, so that the estimate can be used throughout the project life cycle, rather than just giving a final total.
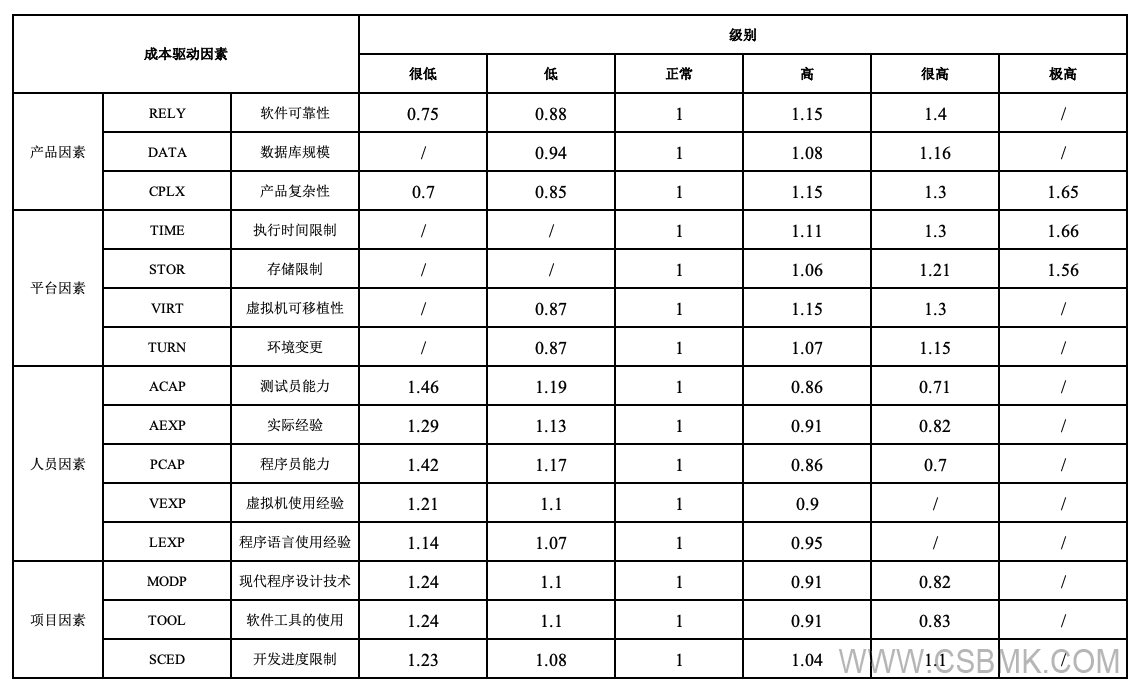
Evolution of key parameters
Redefining "economies of scale" is an important breakthrough in the model. In earlier versions, the relationship between scale and workload was a fixed value. There is an updated method that uses a dynamic power index instead, which is dynamically calculated from five scale measurement factors and can more flexibly reflect the non-linear growth characteristics of projects of different sizes.
Another obvious evolution is the composition of the workload adjustment factor. In the basic model, this factor was simply set to 1. In subsequent versions, it became the result of multiplying four major categories and a total of fifteen subcategories of cost driving factors. This allows the model to keenly reflect the actual impact of various changes in internal and external conditions on workload.
Comparison of function point methods
Unlike the above-mentioned development perspective that relies on the line of code level, the function point method starts from the user logic. It divides software functions into data functions and transaction functions, measures the size of the software by calculating the number of these function points, and then adjusts it in conjunction with system complexity and other related factors.
This method does not care about how it is achieved internally, but only focuses on the functional significance given to the outside world. After clarifying the scale, and then combining the industry with productivity data, the workload and cost required for the project can be calculated. This provides an effective alternative estimation method for projects that are difficult to estimate the number of codes in the early stages.
Applications and limitations of the model
That model and the methods derived from it are essentially parametric equations that work by establishing mathematical relationships between scale, cost drivers and workload. Users have to select a specific model based on the type of project and assign values to its parameters that fit the actual situation to obtain customized estimation results.
Although this model has become a common tool in the industry, its fundamental limitation is that it is centered on the developer's perspective and the behavior of the code. This is very likely to lead to a disconnect between estimates and user-perceived value, and its accuracy may decline in the face of modern software with complex architecture and high degree of reuse. Excessive reliance on historical data for calibration may also make it difficult to adapt to a rapidly changing new technological environment.
In your opinion, in today's software development model that emphasizes agility and rapid delivery, is such a classic cost estimation model still absolutely necessary, or has it gradually become outdated? Welcome to share your opinions and practical experiences in the comment area.


