

Do you know about it? Spark was not created for no reason, but directly targeted at the fatal shortcomings of Google’s Troika (HDFS, MapReduce, BigTable). That is, when machine learning requires repeated iterative operations on data, the traditional framework runs a In each step, the intermediate results must be rewritten back to the disk. Such a design made engineers in 2009 feel extremely crazy. The classic paper of Berkeley Lab clearly stated at the beginning that we intend to do a thing called RDD, so that the data will always be retained in the memory.
The birth moment from paper to code

In 2010, when Matei Zaharia typed the first line of Spark code in the laboratory, the entire big data field was still worried about MapReduce's disk IO. The RDD lineage diagram 16personalities test he drew in his paper has since become a required course for all Spark engineers. No one expected at that time that this memory-based distributed data set would become Apache's top project three years later.
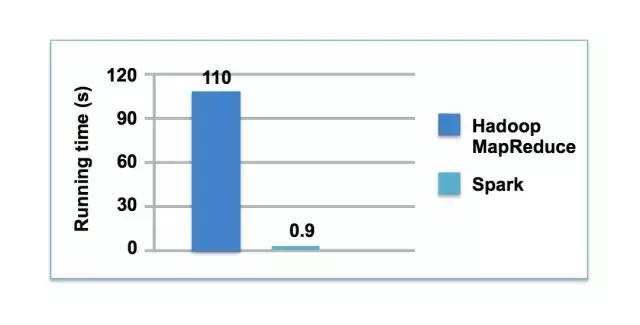
The direct source of the birth of Spark was the actual situation encountered by UC Berkeley. Ph.D. students doing logistic regression realized that every iteration had to read data from HDFS again, and 80% of the time was spent on disk reading and writing. Matei conducted some calculations in the paper. When the K-means algorithm is also run, Spark is 20 times faster than Hadoop. The reason is that the former causes the calculation to actively search for data in the memory instead of repeatedly migrating data between disk and memory.
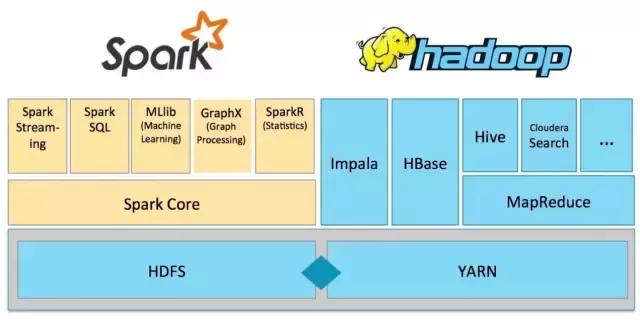
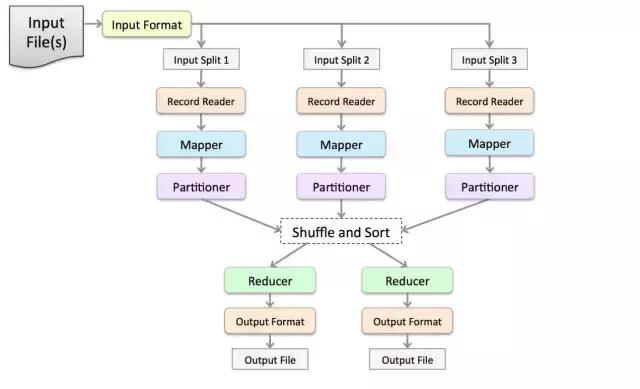
What is a resilient distributed data set
RDD is essentially a read-only collection of partition records. Each partition is scattered in the memory of different machines. For example, if you store "Journey to the West" on HDFS, the first three chapters are on node A, and the middle three chapters are on node B. , the last three chapters are on node C. After Spark starts, it will allocate a piece of memory on each of the three machines and load the corresponding chapters into it. What should I do if node A goes down and the data of the first three chapters is lost? The designer of RDD has thought of this for a long time. It will remember how it was generated from the HDFS file through a series of operations such as flatMap and reduceByKey. It can be restored by recalculating directly on node B.
It was completely different from the coarse-grained design of memory grid products at that time. Other frameworks will copy the data into three copies and store them in memory, but Spark does not do this – it feels that network transmission is more expensive than disk IO, and would rather recalculate after loss than make multiple copies. In 2014, Spark compressed the sorting time of 100TB data to 23 minutes on the Sort Benchmark, relying on this unique design.
The renaissance of functional programming

When you open the Spark source code, you will find that 75% of it is Scala code, 15% is Java code, and the remaining 10% is reserved for Python and R. So why choose Scala? This is because there are no mutable variables in functional programming, and all operations are based on input data to generate new data sets. This feature is inherently suitable for distributed computing. Take word frequency statistics as an example. The process of writing using Spark is like this, first sc.textFile(), then flatMap(), then mapToPair(), and finally reduceByKey(). Each function will not change the original data, but only generate a new RDD.
In a distributed environment, concepts such as anonymous functions and higher-order functions are of great value. For example, if you plan to filter the IPs in the log, write .filter(_.startsWith("192.168")) directly in Spark. This function will be passed to all nodes for execution after being serialized. Compared with Hadoop's method of inheriting the Mapper class and then re-writing the map method, this way of writing directly reduces the amount of code by 80%.

The structured revolution of Spark SQL
In 2013 16personalities Chinese , the Spark team discovered that the most frequent thing users did was to use Spark to process JSON logs and Parquet files. However, the operation of writing RDD directly was very complicated. So, they referred to Google's Dremel paper and encapsulated the DataFrame API in the upper layer of Spark. This change allows Spark to process unstructured logs and perform structured queries like SQL. For example, to count the unique visitors of a website, in the past, you had to write groupByKey and then perform the count operation. However, nowadays, it can be completed with just one sentence of spark.sql("SELECT count(DISTINCT ip) FROM logs").

As the core of Spark SQL, the catalyst optimizer parses SQL statements into a logical plan, and then generates a physical plan based on data distribution. In 2015, when Facebook used Spark SQL to process 300PB of data, it was found that when performing the same query operation, it was 10 times faster than Hive. This was precisely because the catalyst could automatically push filtering conditions down to the data source, thereby reducing the amount of reads.
Evolution logic of machine learning libraries
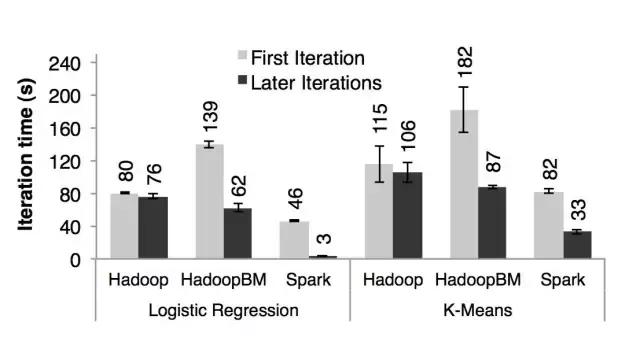
The advent of MLlib makes Spark no longer a pure ETL tool. The traditional approach is to use MapReduce to perform logistic regression, and each gradient descent iteration requires reading and writing to the disk; with Spark, the training data will be loaded into the memory at once, and dozens of iterations are completed in the memory. Netflix used MLlib to build a recommendation system in 2016, reducing the model training time from three days to four hours.
However, MLlib has limitations. It is relatively more suitable for offline training, but not online learning. Therefore, Structured Streaming was later born, using micro-batch processing to simulate stream computing. Uber used this architecture in 2017 to conduct real-time analysis of trip data, capable of processing 100,000 events per second and controlling latency within 1 second.
Spark’s ecological niche today

Now, Spark has become a standard tool for data engineers, but its development has never stopped. The Photon engine launched by Databricks in 2021 used C++ to rewrite part of the execution plan, resulting in TPC-DS query performance doubling again. At the same time, Spark is actually penetrating into the field of AI, such as using TorchDistributor to conduct distributed training of deep learning models on a cluster.
After studying Spark’s ten-year journey from the beginning of the paper to dominating the big data ecosystem, you can imagine what our current big data field would have looked like if Google had not published those three related papers. We are happy to express your opinions in the comment area and like it so that more people can have a glimpse of the story behind this technological innovation.
